At Truebil, I was fortunate enough to be given an opportunity to solve a unique engineering problem. We had already outsourced CRM development to a third party but I had to integrate the data flow to CRM from our product and back. I mentioned earlier that I was given a unique engineering problem because of the challenges it posed. The challenge didn’t lie in the CRM integration alone, but the fact that Truebil has umpteen number of in-house products which spawn data close to about 1 Million data streams per hour. Besides building a bastion of such magnitude, I knew that it would be equally challenging to work with three different verticals and stakeholders. This post is going to be an account of my experiences dealing with two things. First, how Truebil catered to the transfer of a million JSON data stream to and from CRM without hampering its operations and customer support. The second experience deals in the art of working with different verticals. Not that I have mastered the art or something, but I will share my own experiences and learnings in this post.

The solution
We had two problems in hand. First was to send all the data from Truebil to CRM. Second was to receive the data that gets generated in CRM.
We’ll first address the workflow wherein we started off with taming all our data producers. Whereby producers I mean, all our in-house products including (but not limited to) our website, internal data entry website, data-collection app, crones, PWA, customer agent data collection spreadsheets, etc. With a million data streams being generated every hour, we had several tasks in hand and I will list a few of them in the order below:
- Enqueue each data stream – in order.
- Process the data streams and convert each stream as per a data mart, generated jointly in collaboration with our CRM and, operations teams.
- Hit the CRM server in the same order in which the data streams were generated.
Let’s discuss the first task. It was of paramount importance for us to maintain the order of the data streams. For instance, a customer does an action on our website for which a login action is a prerequisite. So we can’t let the former go first and then the latter. Similar case exists with all our producers.
We use gearman for our queue computation. In order to tackle the ordering issue, we maintained only one queue for our entire computation, lest we run the risk of losing the ordering of the data streams.
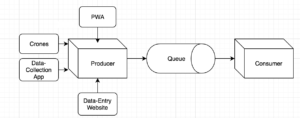
The second task in hand was to process the data streams in a format suitable for CRM consumption. Below are some screenshots to give you a glimpse of how the pre-processed and processed data looks like:
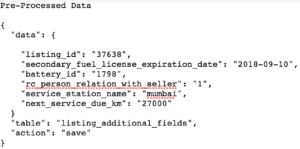
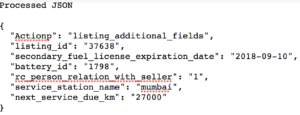
It required a good amount of computation for each incoming data stream. For every foreign key out there in the pre-processed data, we had to get only select amount of content from the related table to make it ready for consumption.
In the third task, after processing the data we had to hit the CRM servers with the processed JSON data stream. We were also supposed to wait for the server to respond with a 200 status and hold other jobs in the queue until then. In cases wherein, where we did not receive 200 status, we used to hold on to that job instead of letting it go and moving on to the next one. It was figured out that the CRM rejects a job and returns a different code only when there is a server issue. While testing the integration, we also figured out that the CRM servers almost always accept the job after a maybe a couple of tries. This could possibly be because of the load that we impose on the CRM servers. Hence, it was decided that the CRM server will be hit with the same job (for which it didn’t return 200 OK status) a maximum of three times in a span of 6 seconds. With each hit, we expected their server to accept our job else we would take down our job server. Simply put, we would cut off the outlet of the queue. This was done so that we do not lose any data stream from our side without CRM’s acceptance. When the worker gets shut down, we devised a solution wherein we would restart our gearman worker after a delay of 10 seconds. This process of re-staring the gearman worker does not involve anyone’s manual intervention. We, instead created a watchdog – a gearman monitor, to keep a watch on the workers and restart if necessary. We also created gearman bots to alert us on slack for every unusual activity that is happening with any of our data processing or with our gearman workers.
The second workflow consists of receiving data from CRM to our end. We maintain another queue at our end for every data stream that we receive from CRM. Each request goes through several stringent data validation checks. Only after a request has passed the data validation checks, we allow it to enter our database.
Our learning
I will break down the learnings into two scopes. First will be about, how Truebil handled building a new product for our operations and customer support team without hampering their daily operations and without loss of any lead. Second, revolves around my personal learnings from this project.
Here at Truebil, this project required a sophisticated setup of a smooth flow of requirements and a clear vision of deliverables, in between all the stakeholders. Lest, we ran the risk of ruining the timelines and a complete messed up CRM. A rogue CRM carries a wide range of repercussions from low leads to low sales. Low sales, goes without saying, leads to an overall risk of everyone’s position in the company. This anecdote was just to portray the gravity of the project. Hence, we had a very capable team of product managers, operations managers and software development engineers. All the stakeholders from the management team did a fine job of setting up an exceptional example of planning and execution. So did the engineering team, in solving complex engineering problems to timely delivery of the actionable.
As far as my learning goes, as a SDE (Software Development Engineer), it was tremendous. Besides solving the engineering challenges that came along, I learnt many more things during the tenure of this project. It was of utmost importance for me to take care of timely deliverables and, ensure no gap in or lack of communication with any of the stakeholders during the entire development cycle. Moreover, my interaction with the different stakeholders including managers at Truebil and a remote development team, had impacted me profoundly. It gave me a deeper understanding of how a product is planned, executed and managed at upper and mid-management levels. I started developing an acumen to pursue product development by a holistic approach, which considers every stakeholder as an end-user of a product. This approach allowed me to imbibe practices which incorporates a well-rounded and balanced perspective in any feature development.
Future scope
There are two major challenges to cater in near future. First one would be to make our gearman servers compatible for massive scaling. The increasing footprint of Truebil across the country, would mean an increase in operational activity and user generated data. This means that our job servers would soon need to handle an estimated 10-20 million data streams an hour. At such scale, there’s a possibility that we might suffer a slowdown in the execution of our jobs. With lack of or no free space available in memcache, we won’t be able to enqueue or dequeue any job(s). Second scope, which in part extends from the first scope, is to lower the load on just one queue. We would want to implement sharding and also maintain order among the jobs.
…………
I have written other blogs as well. You may like to read them from here.
Interesting. I like the way you have put technicalities into words. Definitely worth a read!!
Thanks! I hope to write more.